A recent post demonstrated the succinct and powerful quality of code native to Power Query. The original conundrum is highlighted in the Power BI forum here, and the posted solution no doubt works, but is a little cumbersome.
The Power of M lies in it’s human readability, which not only does not require encyclopaedic knowledge of ASCII or Unicode, but also automatically makes it much easier to customise — all data sets are wonky in different and creative ways.
Many of the functions used here were discovered by simply browsing the Power Query M function reference library (no, really, it’s quite enlightening).
First, the data set from the original problem was recreated, with some additional rows:
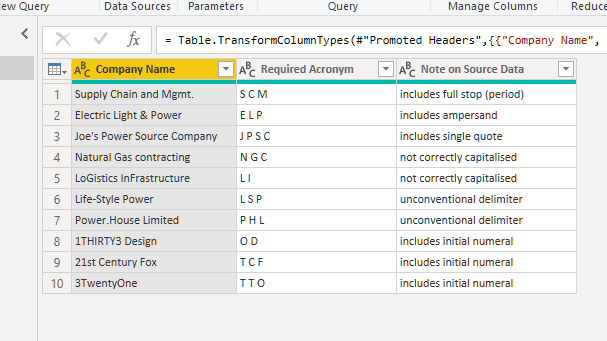
To make it easier to understand the final single line of code (nested here for readability):
Text.Replace(
Text.Remove(
Text.Replace(
Text.Proper(
Text.Remove(
Text.Trim(
Text.Clean([Company Name])
),
{“‘”})
),
” And “,” “),
{“a”..”z”,”0″..”9″,”(“,”)”,”,”,”.”,”-“,”&”,”£”}),
” “,” “)

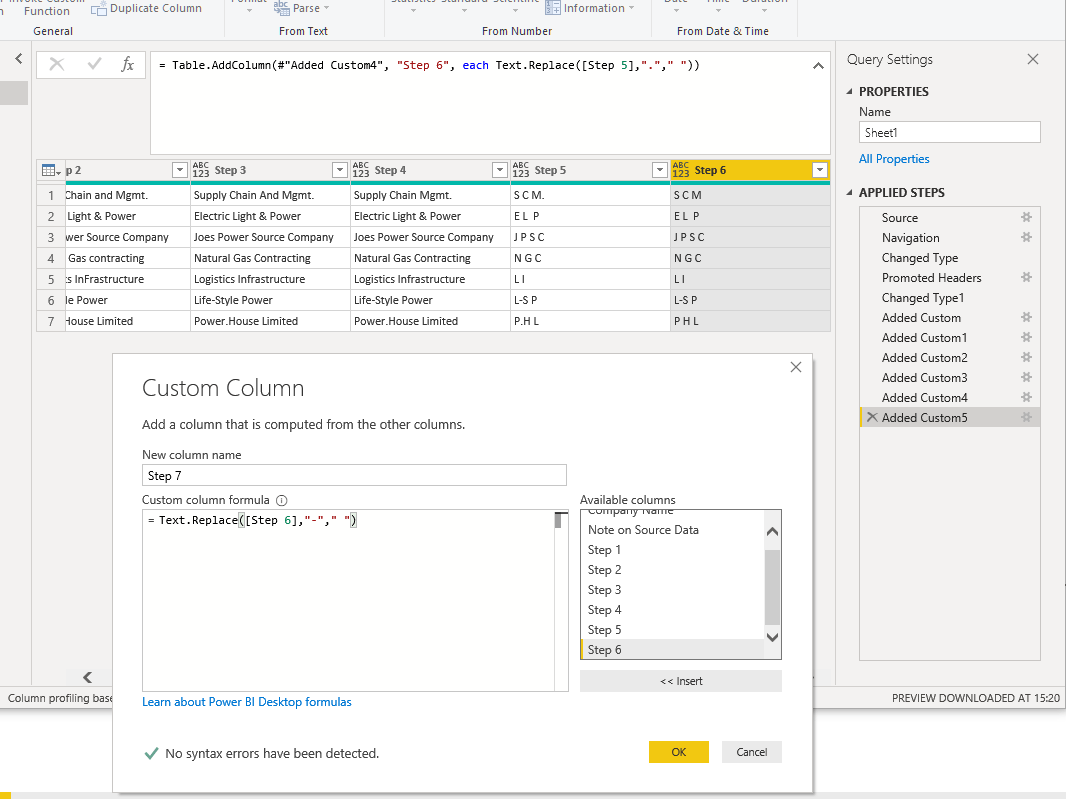
Let’s investigate each step in turn (from inside out), by creating a new column for each.
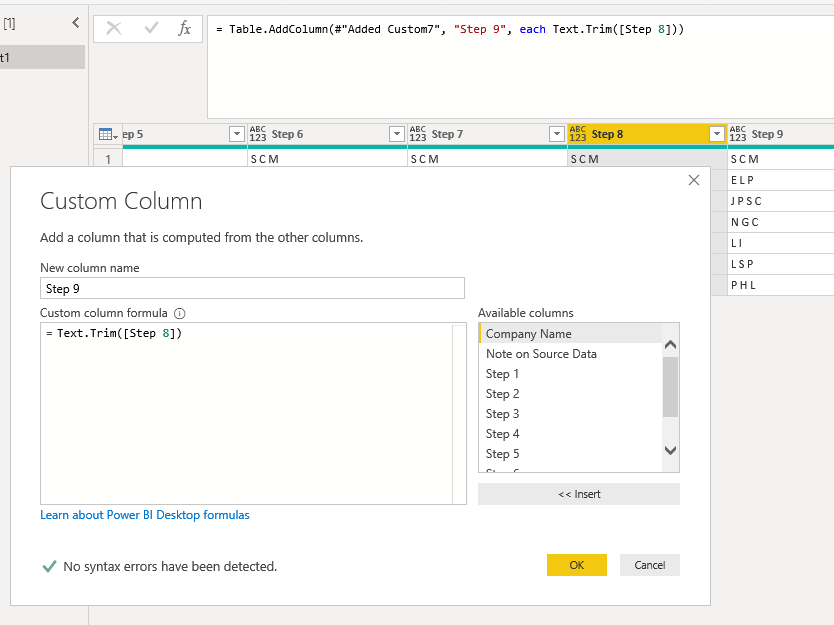
Text.Clean() and Text.Trim()
Does what it says on the tin: removes all non-printable characters…and then removes all leading and trailing spaces.
Text.Remove() Part 1
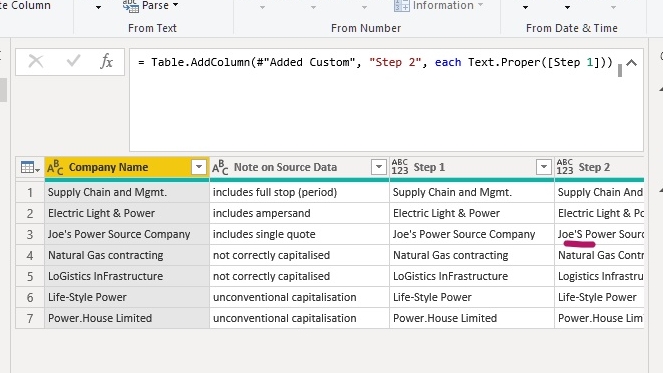
Clear out all the single quotes — this step is needed for this source data as the next Text.Proper() will treat the ” ‘ ” as a delimiter and return the first character following as upper case.
Text.Proper()
Transform the text to proper case, ensuring all initial characters for each sub-string is capitalised — this ensures that poor data entry is managed.
Text.Replace() Part 1
If your data includes words that are not to be included in the acronym, such as “and”, “for”, “of”, etc remove them — remember that each substring has been transformed to proper case. NB if your data contains alternative delimiters, such as hyphens or full stops, replace these with spaces before the next step.
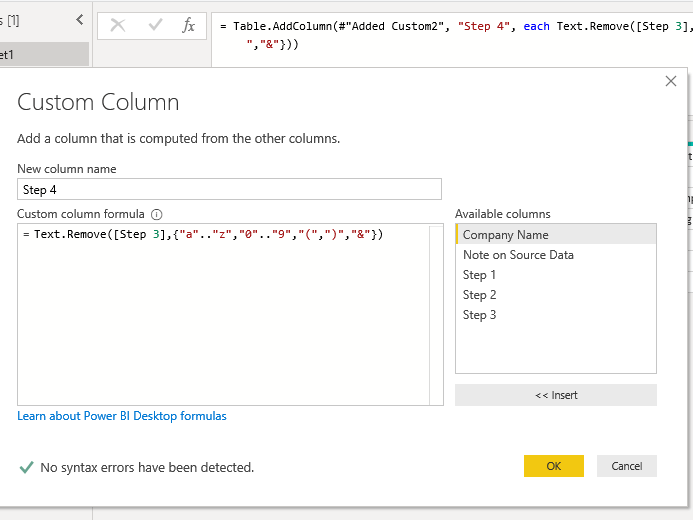
Text.Remove() Part 2
Remove all unwanted characters: lower case a-z, numerals, and any ‘hinky’ stuff: currencies, mathematical operators, non-Roman alphabet characters — depending on your data set.
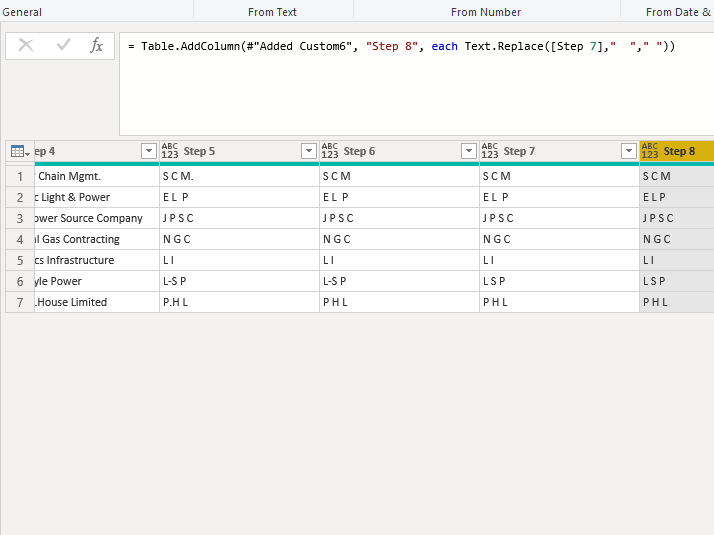
Text.Replace() Part 2
Replace double space with single space — depending on the quality of the data this may need to be repeated.


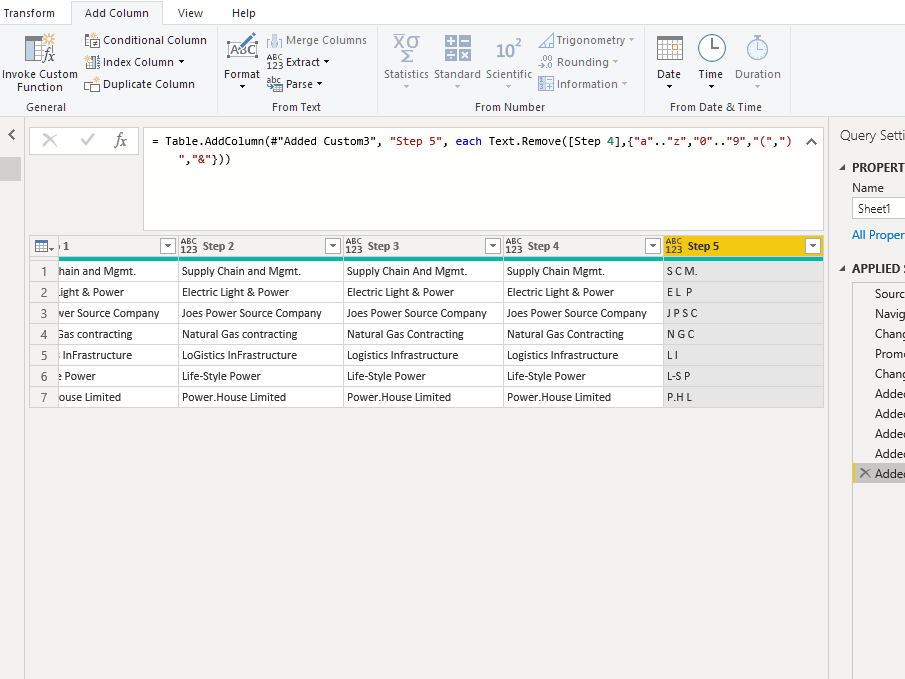
…and then you are done!
Conclusion
Power Query M really does allow you to transform your data before you start modelling. This means that the system resource is called upon at the point of data refresh, not each time your consumers view or interact with a report or visual — depending on your data size and structure, this can considerably reduce computational and bandwidth overhead.
Of course, some data might not be so easily managed: the final three rows of the data set above are a perfect example. However, there are always ingenious solutions to your unique data cleansing or parsing needs.
Another benefit to using M before modeling your data, is restricting the use of DAX to creating measures — where it belongs. DAX is a extraordinarily powerful and deceptively simple — but by no means easy — language. One should never assume it can simply be ‘picked up’ like VBA or Python. Like Power Query M, DAX also has an inspiring function reference library; watch some Alberto Ferrari to find out more.
Finally, your source data will drive the functions you use and the order in which you use them. Some of the steps in this example can be reordered or repeated to suit your data source — for example Text.Trim() in the picture gallery above is Step 9 rather than Step 1a as described above.
Enjoy your M!
